
Easy Data Generation Using Local Models
I'm back! And I'm sending out an early release of the thing I've been teasing for months. Happy New Year!

This has been long overdue.
I mean that in more ways than one: the project I’ve been teasing was originally meant to take a weekend to build, yet took three months to get it into the (still janky, but functional) state it’s in now; and this newsletter was meant to release every weekend, but got delayed — first by final exams, then by the holidays. Furthermore, this newsletter was meant to be a place for me to share what I’ve learned while building stuff, but for a couple of weeks there I mainly reported on what other people did. Now, finally, I’m correcting all these states of affairs.
Augmentoolkit — a Jupyter Notebook where you take some documents and a local LLM and make instructional training data about the documents’ information — is out. I haven’t really announced it elsewhere because I’m waiting for a demonstration dataset to generate; but I want to a) show this off and b) get it out before the New Year. So…
🎉🥳🎉🥳🎉
…Let’s talk about it!
At this point you’ve read a decent amount of writing from me about why data is a pain point for open source model creators. I won’t bore you with more of the same words, I’ll just share this flowchart I made that I think sums up the problem succinctly, as a refresher:
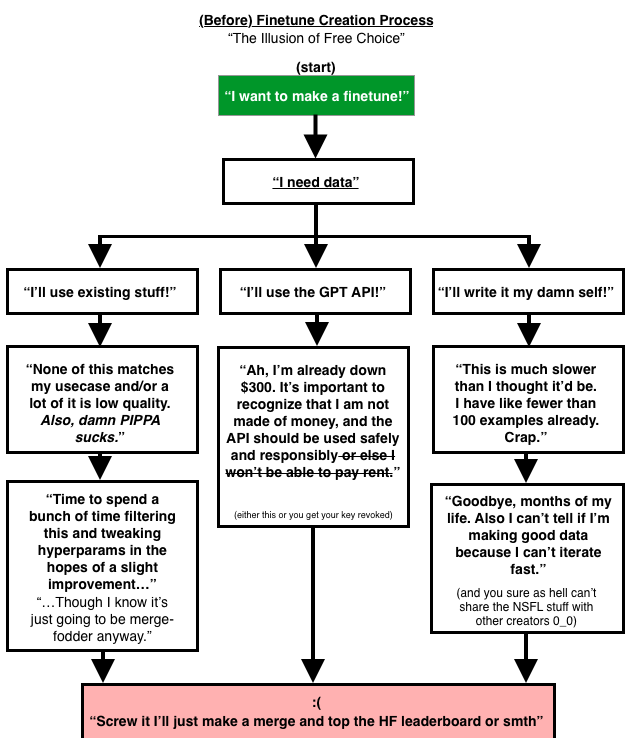
Making data is either expensive, difficult and time-consuming, or generic (and probably low-quality). Data should instead be shareable, fast, and scalable.
Why do we spend so much of our time writing (either editing GPT responses, or creating our own examples) if we’re builders of machines that can write? Why is getting a dataset so damned hard, and often expensive to boot? This is the problem I set out to solve.
Here’s the core of how my solution works:
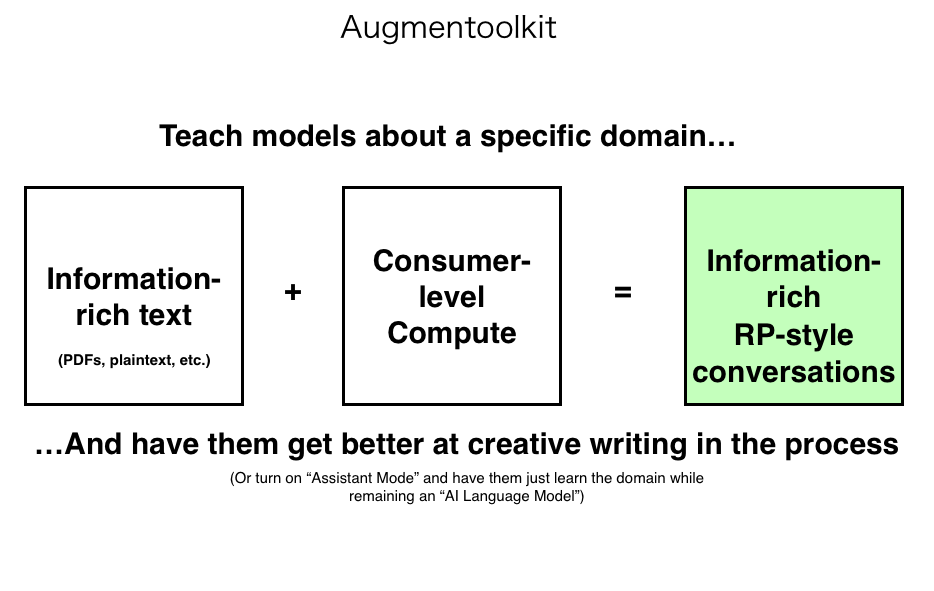
(Why make it create RP-style conversations by default? Because a lot of people use LLMs that way)
Augmentoolkit is my attempt at solving our data problems. Put simply, Augmentoolkit is a way to make instruct-tuning data using compute and plaintext file(s) containing information about a subject. It focuses on accuracy, congifurability, and having a low barrier-to-entry. You can run most of it with a 13b (or all of it, settings-dependent). It's a Jupyter Notebook, so it should be easy to use and debug. It can generate RP-style data or user-assistant style data (though only the former has been extensively refined), so it's suitable for a whole bunch of different use cases.
Augmentoolkit tries to allow basically anyone to make a good dataset about basically anything. At the very least, it shows that an automated approach involving converting human-written text is viable. Here’s a breakdown of some of the key ideas behind it in a more graphical form, presented by the tool’s mascot, Augmentan-2 (since all AI tools seem to have an AI-generated image mascot):

Augmentoolkit is meant to reduce data as a significant pain point for model creators. I want this to help democratize data generation. Even if you can manually write really good data for RP bots, or domain expert bots, or whatever, your writing ability cannot be 10Xed or 100Xed in scale—but your prompts CAN be. And feeding pretraining-style data into an instruct-tuned model as training data, in hopes of making a domain expert, is in no way ideal. This tool allows you to leverage text and writing ability to improve instruct-tuned models. With Augmentoolkit, hopefully, people can combine their GPUs to produce massive datasets that stick around forever (far more parallelizable than distributed training); or act individually to make data in their own niches of interest.
Take some text. Take a model. Get data out. It’s that simple.
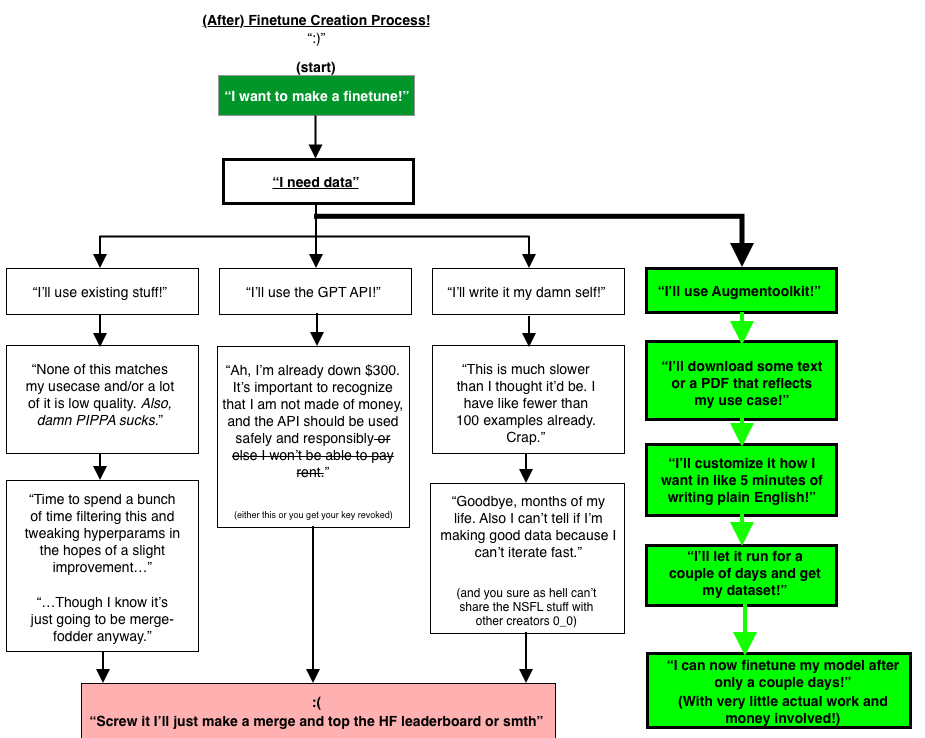
Well, it’s that simple to use. The actual process under the hood is semi-complex (for interest only, you don’t have to read this flowchart, but it might be fun):
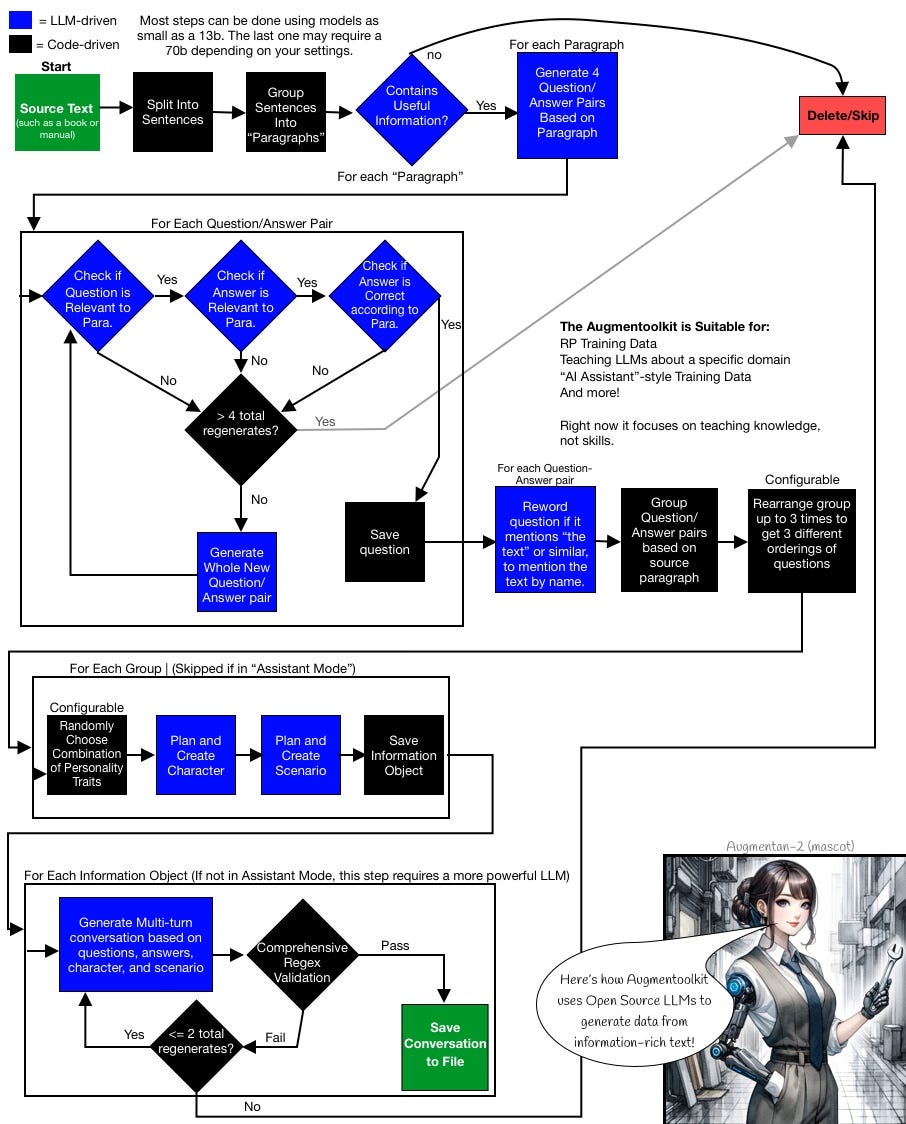
Note that your mileage may vary significantly depending on what source texts you use. And what models you use. I suggest a combination of Q6_K FlatOrcamaid-13b (helluva name, I know) by Ikari, and Q4_K_M Airoboros-l2-70b-3.2.1 by Jondurbin.
Want to make your own dataset using open-source models? Here are some Links:
Demo Dataset (Not yet released, as it’s still generating while I’m writing this, I may edit this post on Substack later once it finishes)
And for the plain text sources, if you have no good ideas: Project Gutenberg. Save a "plain text" version of the book and follow the README instructions from there.
Please tell me if you encounter any bugs or need clarification on anything, so that I can improve the repo.
Finally, if you rent out a GPU to run this, take my advice: do the “2-step” generation approach, and use a 3090 or similarly cheap and fast (but low VRAM) GPU for the first bit, which only needs a 13b, and which will probably take at least a full day for a complete text. Otherwise, you’ll spend a lot more money than you want.
If you have any questions, please drop them in the comments! I’d be happy to help you make datasets using this tool.
That’s all for this week. It feels good to be back! And it feels even better to finally get this released, even if it’s in something of a janky form — it can still be used usefully, and built upon. To paraphrase a certain general, “A good repo violently released now, is better than a perfect repo next week.” Thank you for your patience, and happy New Year!