
How To Make Your Own Augmented Dataset
A Step-by-Step Walkthrough, with Code, for Augmented Data Generation

I’ve talked about human-written and AI-augmented data before on this substack. But the details I showcased in that post are two things: sparse and outdated. Now that Augmental-13b, the refined version of MythoMakise, is out — along with its training code — I can share in detail how to create your own augmented data from any dialogue-heavy plaintext where the speakers are labeled. Since the repo also contains a training script, you can use this to finetune your very own large language model on your favorite story. Provided the training data is in the right format, of course.
If that sounds restrictive, you’re right: I picked VNs for my early experiments because they were already pretty close to an RP format. Basically I made the work easier (and cheaper) for myself, at the expense of generalization. The only other text I can imagine this working on out of the box are movie/TV scripts, with some regex adjustments in the second notebook cell. But I am currently working on a version that can cheaply generate conversational instruct-tuning-worthy data from any plaintext, so look out for that sometime in the next week or two.
Here’s the pipeline we’re going to be working with today.
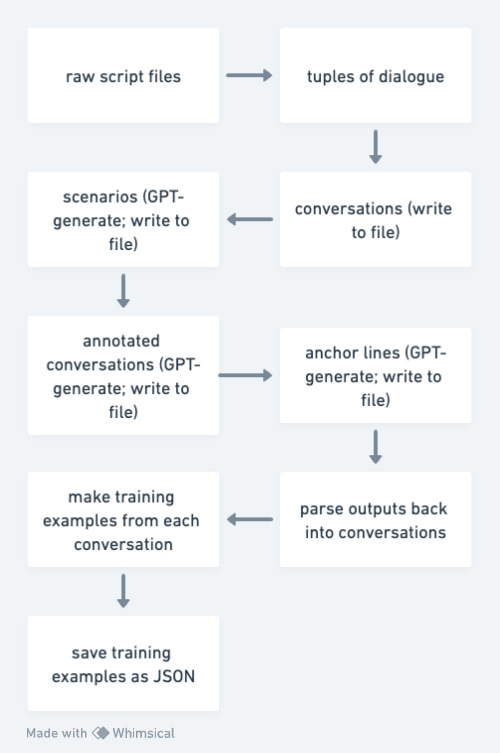
This walkthrough assumes a bit of prerequisite knowledge: Python, Git/GitHub, and Jupyter Notebooks skill. If you have those you should be able to follow along; if not, it might be a bit trickier, but you’ll still probably be able to figure most things out — they’ll just be harder to safely change. That all being said, let’s kick this thing off!
The first thing you need to do if you want to make some augmented data, and don’t want to write your own script, is to clone this repo onto your local machine:
https://github.com/e-p-armstrong/amadeusYou’ll want to have this open as you read (and possibly work through) this article. Then go find `processing_refactor.ipynb`. Open it up in your favorite text editor (which preferably supports Jupyter Notebooks. I know VSCode does).
At the very top of the notebook you should see something like this:
annotated_dataset_has_been_manually_edited = FalseThis is a variable that makes manual edits of the dataset less headache-inducing. The idea is that if you manually delete anything from the dataset files that the script creates (because the script picked some poor paragraphs to make data from, for instance), then you should set this to true. If you just change the contents of the files, for instance during a manual QA pass, this can be left as false: the notebook won’t regenerate files that already exist. Because of this, it’s rather hard to accidentally cost yourself money, or to delete existing data.
Beyond this first cell we have the first code that actually does something meaningful:
import re
testval = 0
# Step 1: Remove Unwanted Strings
# Regex to match unwanted patterns enclosed in []
unwanted_pattern = re.compile(r"\[color index=\".*?\"\]|\[(?!name|line|%p).*?\]")
def remove_unwanted_strings(text):
return unwanted_pattern.sub('', text)
# Step 2: Parsing the text
# I'll update the regular expressions to exclude the delimiters.
name_regex = re.compile(r"\[name\](.*?)\[line\]")
dialogue_regex = re.compile(r"\[line\](.*?)\[%p\]")
monologue_regex = re.compile(r"^(.*?)(?=\[%p\])")
def makecols(str):
global testval
"""Returns a tuple of (speaker, dialogue) from a single line from the script"""
...etc...Remember the pipeline flowchart from earlier? We’ve just done the first two steps. The cell we’re on loads the raw script files and turns them into tuples of dialogue — a line from the text represented as (speaker, line). It reads a text file comprised of most of the chapters of the VN, concatenated together, and turn them into a chronologically-ordered array of these tuples. It also does some filtering to remove empty lines and data about the color of the text that’s encoded in the files that I used as a source — if you adapt this script to read from different material, you’ll probably have to add in your own filtering and make a bunch of changes here. I recommend getting GPT-4 to help you: tell it what kind of text you want to get rid of, paste this cell into the chat window, and it should be able to do the entire task.
Next up, we have another cell that definitely requires modification if you’re using this yourself. Thankfully, though, it’s a pretty small one:
# The character the user is roleplaying as
user_char = "Rintaro"
# The characters whose lines the model will be trained on
model_chars = ["Kurisu", "Luka", "Faris", "Mayuri", "Itaru", "Suzuha",] To make conversations from just a list of every line spoken or thought over the course of the entire source text, the approach I took was to check if any lines were recently spoken by the main character, and one of the side characters I’m training on. If the protagonist and an important side character have said something recently, it’s likely they’re having a conversation that can be turned into training data. This approach worked very well when the notebook was only dealing with one model_char, and it still works decently now that there are multiple, though its quality has dropped off a bit.
When setting the values in this cell, just pick as the user_char the protagonist of the text you’re working with — and add a list of the characters whose lines you want to be training data into the model_chars list. Note that with the current approach, you’ll need to handwrite a character card for each of the characters here, so if you want this done fast you might consider not adding too many people here. And yes, the protagonist’s lines are used as training data too.
Following this cell, we have something you may or may not need to add stuff to, depending on what your source text is like: tuple list processors. Or, more simply: a bunch of small scripts that take a list of tuples that might be generated from raw text by a script, and fix the many, many problems that the naive creation of these tuples resulted in.
# Define Tuple List Processors (before the example generation)
lines_merged = 0
lines_with_space_issues = 0
lines_with_bad_quotes = 0
from tqdm import tqdm # it's not machine learning if there's no progress bar
def remove_only_ellipsis_lines(tlist, index=9999):
"""Remove lines that only contain ellipsis."""
return [(speaker, line) for speaker, line in tlist if line.replace('“','').replace('”','') != "..."]
def merge_consecutive_lines(tlist, index=9999):
merged_tlist = []
last_speaker = None
global lines_merged
for speaker, line in tlist:
...etc...This includes consecutive spoken lines by the same character, double spaces, unconventional quotes, no spaces after punctuation (i.e., “Hello!How are you”), etc. I can’t see why you’d remove any of these, but depending on your source text you might have to add some. GPT-4 should be useful here, I believe it wrote at least a few of them in the original notebook.
Next up, we have the function that I mentioned earlier: the one that takes the list of ungrouped (speaker, line) tuples and outputs conversations. It’s big and complex and you probably won’t have to change it much:
# Create conversations from raw text
from transformers import AutoTokenizer
from tqdm import tqdm # it's not machine learning if there's no progress bar
tokenizer = AutoTokenizer.from_pretrained("Gryphe/MythoMax-L2-13b")
def generate_examples(script, tokenizer, model_char_count_min=1, window_length=10, user_char_count_min=1, max_lines_without_model_char=10):
"""Extracts useful conversations from the script according to a specific algorithm:
1. A conversation is defined as a sequence of lines where the model_char speaks at least model_char_count_min times and the user_char speaks at least user_char_count_min times.
2. A conversation ends when the model_char has not spoken for max_lines_without_model_char lines.
3. A conversation is saved and a new one started if it is longer than window_length lines.
"""
# MAX_TOKENS = 1500 # This produced really really good examples, but they were too large for GPT-4 to annotate while remembering its instructions, so I had to reduce it
MAX_TOKENS = 700 # WORKED EARLIER
# MAX_TOKENS = 800 # EXPERIMENT TO GET LONGER EXAMPLES
examples = []
sliding_window = []
...etc...The only thing you might want to change is the MAX_TOKENS count, which determines how large the conversations extracted can be. The tradeoff here is that setting this larger makes better conversations, but longer conversations are more likely to confuse your annotation AI.
You won’t need to change the next three cells after this. One of them calls the function you just wrote, one of them just inspects an example of a conversation, and the last one filters out conversations that are too short.
Following this, we have a cell that’s essentially insurance.
# Uncomment if you want to read in the conversations from preexisting files
import os
# Previous function to read dialogue from a single file
def read_dialogue(file_path):
speaker_line_tuples = []
with open(file_path, 'r') as file:
for line in file:
line = line.strip()
...etc...The idea here is that since this notebook relies on the indices of the conversation list lining up with the scenario list, the annotated_convs list, and the anchor line list, any change to the conversation list’s parameters, or the source script, can wreck you if you’re not careful — because changing those breaks the alignment and might make it so that all your expensive AI-generated text is now worthless. To prevent this, the notebook writes each conversation to a file (named after its index in the array) in the ./conversations directory. The cell you see here provides the functions (and commented-out functionality) for reading the conversations from said files.
Following this, we have some more cells you probably shouldn’t touch: generate_training_examples, which takes a conversation and makes training examples out of it (defined now so that we can indentify which conversations are very short, and remove them); the cell that calls that function, and the cell that filters out very short training examples (<= 2 replies). You can adjust this last one if you really want to but I would not recommend it.
Following this, we have the fun part: now that we have a bunch of cleaned-up conversations, we can actually start AI-enhancing them to be training data!
But there’s some not-fun setup to do first: you’ll need an OpenAI API key if you want to run this bit, which you can get from their website. If you want quality outputs (and are OK with spending a lot more) you will also need to get GPT-4 access, which requires you to spend $0.50 (fifty cents) on prepaid API credits.
openai_scenario_prompt = [
{"role": "system", "content": """You are an expert scenario-writing and prompt-engineering AI. Your task is to write the context for an interaction between characters from the visual novel Steins;Gate in a "scenario" — a 5-sentence summary about what's happened until the point the interaction STARTS at (writing under the assumption that the reader knows who the characters are and what some of their general traits are). You should use the lines provided to help determine the factual and emotional context behind a given scene.
...etc...The first prompt is definitely something you will want to customize: the scenario generation prompt. Honestly, this is the worst of all three prompts in this notebook, in terms of output quality. But that’s not why you’ll want to change it — you need to change it because unless you’re also generating data from the first Steins;Gate visual novel, you need to change the plot summary provided as part of the prompt. The point of the scenario stage is to get GPT to identify what the context behind each scene being annotated is, so that future steps can make use of that emotional and factual context. To that end, I included information about what the overall plot of Steins;Gate is as part of the prompt. However, since you’re probably doing some different text, with different characters, you’ll likely want to revise this summary to describe the plot of your source text. You also might want to change the in-context example of what a good scenario looks like, to an example from your source text, to further reinforce GPT’s idea of what its task is and what its outputs should look like. So basically, you’re rewriting a lot of this. You can get GPT-4 to help though, that’s what I did.
Following this cell, we have some code that takes the prompt defined above, sends an API request, and writes it to a file. If you’ve used the OpenAI API before this will look very familiar; it’s just that except it avoids making an API call if the destination it would write the file to is already occupied. To help avoid accidentally spending hundreds of dollars:
# A FUNCTION THAT LETS YOU CALL OPENAI ON ALL THE EXAMPLES
import openai
import os
def write_context_to_file(training_data_example, destination_directory, example_index): # for easier inspection
"""Writes a training example (conversation, the full thing) to a file in the destination directory, so that the input for a scenario can be inspected"""
full_conversation = training_data_example[-1]
context = '\n'.join([f'{speaker}: {line}' for speaker, line in full_conversation])
filename = os.path.join(destination_directory, f'{example_index:03d}_conversation.txt') # I'm paying for the tokens, I damn well want to see them
# Write the scenario to the file
with open(filename, 'w') as f_1:
f_1.write(context)
if not annotated_dataset_has_been_manually_edited:
for idx, content in enumerate(training_data_conversations_filtered):
"""Write all training examples to indexed files"""
write_context_to_file(content, 'conversations', idx)
def create_scenario(training_data_example, destination_directory, example_index):
"""Creates a scenario for a training example and writes it to a file in the destination directory"""
full_conversation = training_data_example[-1]
context = '\n'.join([f'{speaker}: {line}' for speaker, line in full_conversation])
if not os.path.exists(os.path.join(destination_directory, f'{example_index:03d}.txt')):
...etc...And then the notebook creates a scenario for each conversation that’s been processed from the text:
if not annotated_dataset_has_been_manually_edited:
for idx, content in enumerate(tqdm(training_data_conversations_filtered)):
# write_context_to_file(content, 'contexts', idx)
create_scenario(content, 'scenarios', idx)
print("\nBeginning Second Pass...\n")
for idx, content in enumerate(tqdm(training_data_conversations_filtered)): # run it again to catch everything that failed the first time. The fact that already-generated scenarios are skipped means this doesn't cost any unneeded money.
# write_context_to_file(content, 'contexts', idx)
create_scenario(content, 'scenarios', idx)When adapting prompts to your own source material, be sure to test out the new prompts on the kinds of input they would usually receive in the OpenAI playground before running the full data generation notebook — this kind of experimentation can save you a lot of money you’d waste generating broken stuff with bugged prompts otherwise.
That being said, let’s skip to the next non-self-explanatory code: the annotation prompt. This is the crux of the data generation notebook — it’s the part that takes lines in a non-RP format, and turns them into lines in an RP format, which also have actions to liven up and enhance the original.
The prompt for the annotation step will probably require less modification than the scenarios one, but you’ll still want to change all mentions of Steins;Gate, the example of creating an anchor line (more on that later), and some of the “detailed instructions” to match the kind of text your raw source material is going to look like:
You are an expert roleplaying AI with deep understanding of internet roleplay formats and extensive writing ability.
- Your task is to convert raw text from the Visual Novel Steins;Gate into a roleplay format.
- You will add physical actions done by the characters to their lines in a compelling, narrative way, that makes sense in the context of the scene you're modifying.
- Actions should be surrounded by *asterisks*, and spoken things should be surrounded by "double quotes".
- You may also find it useful to add non-action, non-dialogue text to characters' responses, (such as 'she says' or other such generic connective terms) to make sentences make sense.
- Do not change which character speaks any given line.
All lines should be adapted to be in the first person, e.g., *I do X*.
Some lines are very important and have a lot of narrative/emotional weight. You may dramatically overhaul some lines to be stunning anchors of the scene. Here's an example:
\"\"\"
Kurisu: "Sigh... You still haven't made up your mind? You like Mayuri, don't you?"
\"\"\"
The context behind that line is that Kurisu is asking Okabe whose life he is going to save — hers or Mayuri's — near the end of the Visual Novel. It's in the middle of a very tense and emotional scene. You could enhance it to become:
\"\"\"
Kurisu: *I hesitate, my fingers tracing a pattern on the cold concrete beneath me, as if it could somehow help me find the right words. My breath catches, and I feel a sting in my eyes. It's a vulnerability I seldom let myself feel.* "Sigh... Have you still not made up your mind?" *I search Okabe's face, looking for an answer, my voice trembling but firm.* "You like Mayuri, don't you?" *I muster every ounce of courage to ask the question, needing clarity in this whirlwind of emotions.*
\"\"\"
You can write as much as you want, conciseness is not a priority. Try to add at least 2 sentences of *actions* to every line you are given.
Some detailed instructions:
- Spoken words in the original should be left intact — you're adding to the script, not undoing it.
- Add actions and novel-like connective text to make dialogue more roleplay-like.
- Ensure continuity at all costs. If you ended up cutting or changing something for some reason, make sure that the lines after it make sense.
- Remember to write all lines in first person, no matter who the speaker is. E.g., do Mayuri: "Tutturu!" *I say as I walk into the Lab, a warm smile on my face. I'm so happy to see everyone~! I hope everyone is having a good day today~* instead of Mayuri: "Tutturu!" *She cheerfully greets everyone as she enters the room, exuding her usual cheerful aura.* Additionally, as in this example, make sure the thoughts/*actions* of each character match the personalities of the character.
- Outline the roleplay scene before writing.
- Analyze the dialogue to understand what's happening physically.
- Brainstorm character actions to reveal emotions and thoughts.
- Start roleplay text with "Roleplay:".
- For interrupted sentences, split and insert the interrupting action.
- Example: Okabe: "I'll find a way to--" *I don't get the chance to finish my sentence* \nKurisu: *I snatch Okabe's phone out of his hands.*\nOkabe: "What are you doing!?" *I stammer at Kurisu.*
- The interrupting character should not say new things—they should only do *actions.*
- Also note that characters write in first person, but refer to other characters by their names or pronouns.
- Add *actions* to the ENTIRE scene.
- If a scene transition (for instance, Okabe and Kurisu leaving an assembly hall) can be explained with an *action*, add one that makes the transition between scenes manageable.
- If there is any sort of transition between scenes, turn it into a long, descriptive *action* by Okabe that explains what happened in the interlude. However, whenever a character is speaking or taking *action*, their line must start with "TheirName:" in that format exactly. Anything else will break the script that is parsing your outputs so be careful about this.This isn’t the entire prompt, however — there’s also the bit at the end. Remember the post I made that mentioned the “lost in the middle” effect a bunch? Here we have a bunch of insurance against that.
Dialogue for reformatting:
\"\"\"
{context.replace("Rintaro:", "Okabe:").strip()}
\"\"\"
## Be sure to remember:
1. Lines from UNSPOKEN represent narration of actions or thoughts from Okabe's POV. If it makes sense for one of these to be turned into an *action* by a character, do so. Be sure to always use first person.
2. Don't leave any UNSPOKEN lines on lines by themselves; all actions and narrations must be part of a character's line. Please, do not write "UNSPOKEN" at all in your response.
3. Every line you write in the roleplay must have a Character: saying it.
4. BE SURE to write the CORRECT speaker for any given line, I have seen a few cases where you accidentally switch who is saying a line and that messes up the whole scene. This applies to thoughts and actions too: Okabe should never *think* in the middle of other characters' lines, for instance. This avoids breaking the roleplay rule where people shouldn't act out other people's characters for them.
5. Remember that all lines should be adapted to be in the first person, e.g., *I do X*.
6. IMPORTANT: the writing should be powerful and nuanced, conveying small details that reveal characters' motivations, personalities, and thoughts, often without overtly stating them — it should be deep and poetic at once, and ought to make up for the lack of a visual element in plain text. Write powerfully, but not pretentiously.
7. In your planning stage, explicitly mention the archetypes/personalities of each of the characters involved, and take brief notes on what word choices/writing styles you'll write their *actions and thoughts* in, considering that information.
8. Be varied in the *actions* you add. DO NOT just focus on facial expressions and the eyes: sounds, slight movements, sighs, recoiling or leaning forward... instead of being repetitive, be DIVERSE AND COMPELLING in your writing. Characters might interact with items in the area around them; you can embellish here and add things that aren't explicitly mentioned in the original scene, so long as it makes sense. And again, match the personalities of the characters involved: dramatic characters are flamboyant; shy characters are often quiet, etc. However characters have nuance: even flamboyant characters can be depressed and worn out under trying circumstances, and you should look out for this, always using the emotion most fitting for the situation and character.
9. All *actions* and *thoughts* should be written in first person for the character that's doing/thinking them. E.g., Mayuri: *I clap my hands together, my eyes wide and bright with anticipation.* "Let's try sending more!"
10. Do NOT forget to write out your plan/thoughts/brainstorming before outputting the final roleplay, and mention in this plan which 1–2 lines will be anchors, and what thematic direction you'll take them in.10 bullet points is way too big, and this prompt could definitely be optimized more; but this size of prompt was a deliberate choice in favor of consistency over efficiency. I bet it could be done even better with a complete revamp, but this is what I iterated on, so if you want to avoid reinventing the wheel, you can use some variation of this. Otherwise, the actual code for this bit isn’t too different from that of the scenario code, and I’ll skip over it. Note how no scenario is included in the prompt for this stage — this is a deviation from the original MythoMakise data generation prompt, and one that I found in testing actually improved the quality of the outputs. Since the changes to each line are not full-blown paragraphs (unlike in the anchor-annotation stage) GPT-4 is usually smart enough to infer the more simple emotional context on the fly.
Some of the next cells deal with reading and processing the produced annotated conversations, from the files they were output to. This all very much resembles the stuff that originally read the script from a file and processed the tuples; some of those functions are even reused. You can add more processing functions if you find it useful.
# A short guide to some of the functions in the following cells
# Define a different read function modified for annotated filenames:
def read_all_dialogues_annotated(directory_path):
# List to store all dialogues (each dialogue is a list of tuples)
# ...etc..., this reads the annotated convs
def delete_all_unspoken(tlist,index=9999):
# You might want to keep this function, you might not, depends on your source text
def generate_consecutive_combinations(sentences):
# A helper function for a later processing function. Don't touch.
def actionize_unspoken_lines(tlist,index=9999):
# Sometimes GPT-4 got confused by monologue in the source script, and would write them during its annotation as "actual spoken dialogue." This is a problem, but it was mostly solvable thanks to the fact that the spoken lines were usually direct quotes from the (internal) monologue.
# This function searches for any direct quotes from monologues, that have been made dialogues, and turns them back into *actions* or thoughts.
def concat_consecutive_actions(tlist, index=9999):
# does what it says on the tin. Any *I do this.* *Then this.* that results from either appending of consecutive lines, or faulty generation, are merged to *I do this. Then this.*After all of this, the processing functions are then called (in a very deliberate order). Finally, we go onto the final GPT-annotation stage: anchor lines.
Anchor lines were an innovation with Augmental that the original MythoMakise didn’t have at all. The intent was to take advantage of GPT-4’s excellent writing ability for long replies by choosing four lines from each conversation and rewriting them at near-paragraph-length. GPT does the choosing because it has a decent narrative sense. This is where the scenarios come in — emotional context is needed if lengthy descriptions of character thoughts and actions are going to be added.
# System prompt:
----------------
You are an expert creative writing AI with deep understanding of internet roleplay formats and masterful writing ability.
You will be given a modified scene from the Visual Novel Steins;Gate. Each line spoken is numbered. Some lines in this scene are very important and have a lot of narrative/emotional weight. Your goal is to pick one or two of the numbered lines, based on relevance and content, and rewrite the *actions* of those lines to make them stunning anchors of the entire scene. This will be accomplished through a mixture of embellishment, creativity, and expansion of the original line.
All lines should be adapted to be in the first person, e.g., *I do X*.
Here's an example. Consider the line:
\"\"\"
Kurisu: "Sigh... You still haven't made up your mind? You like Mayuri, don't you?" *She looks away, seemingly frustrated but also concerned.*
\"\"\"
The context behind that line is that Kurisu is asking Okabe whose life he is going to save — hers or Mayuri's — near the end of the Visual Novel. It's in the middle of a very tense and emotional scene. You could enhance it to become:
\"\"\"
Kurisu: *I hesitate, my fingers tracing a pattern on the cold concrete beneath me, as if it could somehow help me find the right words. My breath catches, and I feel a sting in my eyes. It's a vulnerability I seldom let myself feel.* "Sigh... Have you still not made up your mind?" *I search his face, looking for an answer, my voice trembling but firm.* "You like Mayuri, don't you?" *I muster every ounce of courage to ask the question, needing clarity in this whirlwind of emotions.*
\"\"\"
Make sure the *thoughts*, *actions*, and word choice of each anchor line match the personalities of the character speaking/doing the line.
Maintain the Character (number): line format of the line(s) you change. Ensure the enhanced line doesn't break the scene's continuity.# User prompt:
------------------
Scenario/setting: \"\"\"{scenario}\"\"\"
Text to add some good anchors to:
\"\"\"
{context.replace("Rintaro:", "Okabe:").strip()}
\"\"\"
## Be sure to remember:
Recall that your task is to find 4 important lines that can be lengthened and embellished significantly, so as to give greater impact to important parts of a scene through absolutely stellar prose that makes up for the lack of a visual element in the plain text. The writing should be powerful and nuanced, conveying small details that reveal characters' motivations, personalities, and thoughts, without overtly stating them — it should be deep and poetic at once. About 4–5 sentences long (60-70 words per enhanced line). However, for the sake of ensuring continuity with the original scene, don't change the words that are spoken.
1. Write using a variety of words and immense stylistic flair appropriate to the scene. Be creative and prioritize making the new lines compelling instead of 100% accurate to the original. Alternate short, snappy responses with long and detailed prose to give the text a good rhythm.
2. BE SURE to write the CORRECT speaker for any given line, I have seen a few cases where you accidentally switch who is saying a line and that messes up the whole scene. Also, do not break the important roleplay rule whereby characters should not act on behalf of other characters: Okabe should not think or take *actions* during one of Kurisu's lines, for instance. No one but the character whose line it is should speak on that line. And of course don't change the words that are "spoken" in your enhanced lines.
3. In your planning stage, explicitly mention the archetypes/personalities of each of the characters involved, and take brief notes on what word choices/writing styles you'll write their *actions and thoughts* in, considering that information.
4. IMPORTANT: the writing should be powerful and nuanced, conveying small details that reveal characters' motivations, personalities, and thoughts, often without overtly stating them — it should be deep and poetic at once, and ought to make up for the lack of a visual element in plain text. Write powerfully, but not pretentiously.
Before you begin, you should plan out and brainstorm your approach. In your planning stage, explicitly identify lines you are going to radically enhance with extra-long actions to serve as the "anchors" of the scene. These anchors, after you add your extensive, prose-like *actions* to them, should end up being at least 60 WORDS long, and very compelling. Mention in your plans which 4 lines will be anchors, AND what thematic direction you'll take them in.
Don't rewrite the entire text: just add your new high-quality lines, with the correct line number. Write out the original lines that you're changing in your brainstorming step so that you can better remember what their contents are and can be sure to not forget any "dialogue".You’ll want to change any mentions of Steins;Gate, and the examples, to things more fitting to your source text. Explicit formatting instructions will also have to be customized to your needs. But otherwise, this should mostly work out of the box. If you aren’t very good at writing, go over to ChatGPT and give it a line and prompt it to enhance that one line, and then use the enhancement in this prompt as your exemplar. You can use AI to generate the generalizable example you use in 1-shot learning if you just use a different, specific prompt for that one example.
The code here is similar to the other two API calls and I won’t go over it again. You probably don’t need to change that.
# make anchors
if not annotated_dataset_has_been_manually_edited:
for idx, annotated_conv in enumerate(processed_annotated_conversations):
try:
create_anchors(annotated_conv,"anchors",idx)
except:
print("Error in " + str(idx))
# modify processed examples to have the new anchor lines
# happens regardless of whether we're doing this the first time or not
for idx, annotated_conv in enumerate(processed_annotated_conversations):
filename = f"anchors/{idx:03d}.txt"
with open(filename, "r") as f:
newlines = extract_anchors(f.read())
print("At idx: " + str(idx))
for line in newlines: # modify processed_annotated_conversations in place. I don't have to reread things from files now.
print("At line: " + str(line[1]))
processed_annotated_conversations[idx][line[1]] = (line[0], line[2])The anchors are extracted from the AI response using a regex that searches for the line number; the line number in the original conversation with (that index - 1) is then replaced with the line number of the generated anchors. One thing Augmental-13b turned out to be good at is long, emotional responses, so I think these worked out beautifully. I’m definitely going to try and keep this step in future projects like this one, though technically, the anchor lines are optional if you’re strapped for money or time.
At this point, we’re done with API calls! We process the generated anchors:
# merge lines and such again, in case of errors. Watch for output here, there shouldn't be any.
processed_annotated_conversations = list(map(call_multiple_processors(remove_only_ellipsis_lines,merge_consecutive_lines,add_space_after_punctuation,replace_odd_quote), enumerate(processed_annotated_conversations)))And then take all our AI generations (whose indices are hopefully lined up) and output them as a JSON list file.
# In case this hasn't been run already, due to the flag being set (the number of training examples in the annotated dataset/scenario files may be different than the number generated by the script if the user deleted some manually) we can run it here
if annotated_dataset_has_been_manually_edited:
def make_scenario_list_trainingdata():
scenario_list = []
for idx, content in enumerate(processed_annotated_conversations):
with open(f"scenarios/{idx:03d}.txt", "r") as f:
scenario_list.append(f.read())
return scenario_list
scenarios = make_scenario_list(processed_annotated_conversations)
# Whole process text loop again, turn into tuple list
# Create training examples (again)
training_data_conversations_annotated = list(map(generate_training_examples, processed_annotated_conversations))
training_data_conversations_annotated = [[subsublist for subsublist in sublist if len(subsublist) > 1] for sublist in training_data_conversations_annotated]
# Helper that creates JSON object for a training example at a certain index (annotated history, annotated completion, scenario)
def create_json_object(annotated_conversation, example_index):
last_speaker, last_line = annotated_conversation[-1]
return { # or something like this
"history": '\n'.join([f'{speaker}: {line}' for speaker, line in annotated_conversation[:-1]]), # Since spoken lines probably don't have newlines, we can safely split at newlines to get the speakers back from the json
"completion": f'{last_line}',
"speaker": annotated_conversation[-1][0],
"scenario": scenarios[example_index],
}
### DEFINE BLACKLIST
index_blacklist = [11]
###
# Turn annotated conversation into list of json objects for eventual use in the training script
final_examples = []
for idx, conv in enumerate(training_data_conversations_annotated): # conv is a list of lists of tuples
if (idx in index_blacklist):
continue
for ex in conv: # ex is a list of tuples
final_examples.append(create_json_object(ex,idx))
import json
with open('final_dataset.json','w') as f:
f.write(json.dumps(final_examples, indent=2))
The only thing for a user of this notebook to, well, note at this point is the index_blacklist variable. If some generations are just hot garbage, and you don’t want to regenerate them (probably because they’re based on a crappily-chosen conversation, or one that doesn’t work for specific reasons) you can specify the index of the example here and it won’t be included in the final dataset.
At this point, if you’ve been following along, you should have everything set to generate your own AI Roleplay dataset based on some arbitrary source text! Grab a hot drink and watch the API calls get sent. When they’re done, go and write a character card for each character in model_chars over in make_card_evanchat.py, and then run train.py with all the relevant files copied over to an instance provided by your compute provider of choice!
Word of advice though: you’ll want to manually inspect the first few files that each API call writes, as it’s writing them (the outputs are written to files as they complete). This is because things in production are always different than how they’re tested — so even if everything worked nice in the playground, your prompts may be generating hot garbage in actuality. And you don’t want to spend hundreds of dollars on hot garbage, so look at the outputs and catch these errors early.
And that’s the other thing: this is fairly expensive to run right now. It cost about $272 for me to generate a (nearly) 8000-row dataset. Now, by normal dataset generation standards, this is actually pretty good — it produces a labeled, multiturn dataset, with a variety of characters’ perspectives. It’s certainly faster and less costly (opportunity cost) than doing the entire thing by hand, like some people do. But despite the fact that this is relatively cheap to run, it’s still not absolutely cheap, so do bear the costs in mind. I’m working on a version of something similar that will use open-source LLMs right now, which will hopefully be much much cheaper and have about the same quality.
Anyway, this has been a deep dive into the Augmental dataset generation code, and how you can hack it for your own needs! Tell me what texts you want to turn into training data in the comments! There’s some good inspiration over at this Reddit comments thread if you need it. And if you have any questions or thoughts, do let me know!
Finally, consider subscribing to this substack (it’s free). I plan on doing more deep dives like this into my future AI projects, so if you’re interested in using those, putting your email down is definitely worth it, I think.
Have a good one and see you next time!