
LLM Training Principle: More than the Sum of Their Parts
2+2 can equal 5, or 50. Learn how to use this to make better AI.

If you’re looking at data you’re collecting or making for an LLM, you probably consider each piece in isolation. “I have some medical data, and some poetry data. Now the LLM will be able to answer medical questions, and also write poetry.”
But there’s something I’ve learned while creating AI that we’re going to discuss today: They can compose and combine the information they learn. LLMs learn from all their training data. They distill the truth and patterns behind what they see, rather than a crude memorization. They are more than the sum of their parts.
If you train an AI on medical data, and on poetry data, it won’t merely be able to diagnose your issue in one chat and write a regurgitated poem in another one. That AI will be able to write poems about medicine. It can combine its knowledge, and use its understanding, to create entirely new outputs. In this post, I’m going to share with you a principle and observation I’ve used while creating numerous LLMs in different fields.
Specifically:
LLMs can combine
LLMs can understand — if you let them
You can train intelligence and logic into these things
Interpolation is easier than invention — for knowledge and logic
As usual, all of this is based on my own experience, observation, and intuition. It’s meant to be practical, “tactical” advice. I’d bet that interpretability researchers have found out similar things; if anyone has some good papers from there, please do recommend them in the comments!
Let’s talk about what LLMs can do when we teach them properly.
LLMs can combine
If you train a model on conversations where it does A, and conversations where it does B — then if you ask it to first do A and then do B, it probably can.
For example, I recently trained a model for an open-source crypto community (we’re releasing it and all the code soon). The AI was trained on a combination of “generalist” assistant data, from datasets such as evol instruct, unnatural instructions, and Alpaca-CoT, as well as a bunch of domain-specific QA (question-answer) data about the crypto community’s work that I generated using a custom fork of Augmentoolkit. Come inference time, I could ask the AI to write a poem, or an essay, about the crypto community; even though the model was only trained to answer questions, it was also capable of writing the poems, and decent ones at that. This is what I talked about in the intro to this post. However, “combining” doesn’t stop here.
It’s not just about mixing and matching format with content. For this same AI, we had to train it to refuse questions about information that changes constantly, such as the number of nodes on the network, or the price of the crypto coin. The only alternative was hallucinating this information, which is obviously not ideal if finances are involved.
To address this, I generated a handful of synthetic conversations where the AI was repeatedly asked questions about current information, and promptly refused to answer these questions. However, these conversations did not include any legitimate questions — they only had questions and refusals. I trained the AI on these conversations, alongside the normal question-answer factual conversations. On the inference side of things, I adjusted the prompt with a short example of a legitimate question with a legitimate answer, as well as one instance of a question about current info answered with a refusal (to activate the latent space about each task). The result?
The AI could answer a legitimate question in one “turn” of conversation and refuse to answer a question about current information in the next “turn”, even though it had never done the two tasks together during training.
LLMs can combine many things into one response, and they can combine different responses into one conversation. Seamlessly. The latter may require some targeted latent space activation, especially if there is not much training data for certain kinds of tasks (e.g., refusals — there are only so many ways to say “no”) but it’s still a possibility and that makes it powerful.
LLMs can Understand
Here’s the intuition I use: AIs do not merely regurgitate words: they learn the underlying patterns behind the information they see, if such patterns exist. Learning these patterns helps them respond correctly in different situations. Prompt engineering is the art of starting off a pattern that, when completed, produces a correct result. But in training, we create the patterns that the AI understands.
Complementary patterns reinforce the resilience and intelligence of the LLM. Contradictory patterns make it unstable. But overall, the AI you are training can get the “big picture” of something, even if it only sees disconnected parts during training. Train it on a wiki site and a documentation site (that occasionally mention each other) and ask it about where you can go to learn more, and it will tell you about both. It’ll probably also refer to itself as a place to get help, because the AI has learned that it is a helpful source of information on that subject. This is sort of combination, but at a larger scale: my intuition is that, if you train an LLM on a subject, even by only showing it disconnected parts, and then activate its latent space with a large system prompt — then the AI gains a “birds eye view” of the information it has been taught.
This might be exemplified better by a “holy crap” moment I had a while back, while training an AI on my own writing. I asked the AI what it had been trained on, and it gave a correct answer. That information was not in the training set, but somehow it told me it knew my book, my blog, and my personal notes. When I say the LLM learns from all its training data, this is what I mean: it learns a pattern from all of the data, that none of the training data contradicts.
Here’s a visualization. You know how you can fit a function around some points?

Here’s my intuition. Imagine the blue dots are LLM behaviors demonstrated by the training set, and the red triangles are contradictory behaviors. The circle represents the LLM’s range of behavior — how it usually acts. When you train an LLM using supervised finetuning, I view it as adjusting its understanding — the underlying patterns it knows how to complete — into a structure that lets it complete all the patterns it saw in the training set.
In the case of a question-answering AI, let’s say the behaviors it has seen are answering questions. Its range of behavior includes what it has seen in the training set. This leads to the similar, but undesired behavior of answering questions about information that changes rapidly, being part of the LLM’s range of behavior.
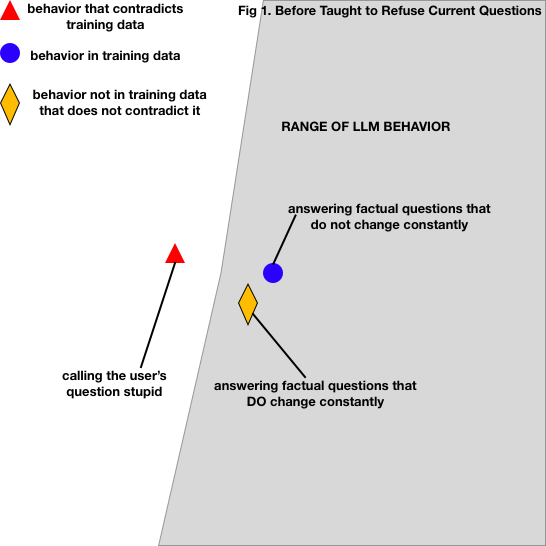
So we adapt. We add more training data, which shows a different desired behavior, and is mutually exclusive with the undesired one. You can’t answer and refuse a question at once: adding refusals contradicts enthusiastic answering.
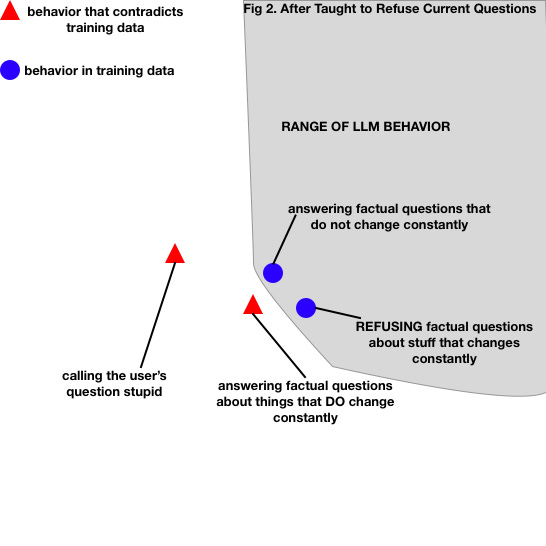
By training the LLM, we adjust its understanding to include behaviors that the data demonstrates, and to reject behaviors that the data contradicts. That’s my intuition behind it.
I like this intuition because it lets you intuitively work with a very complex system to what appears to be a decent degree of accuracy.
Even though fitting a simple function to datapoints has FAR fewer dimensions than LLMs do, individual datapoints are also *far* simpler than as abstract a concept as a “behavior” is for LLMs. Maybe the complexity of the points on this “graph” cancels out the complexity of the “function” we fit to it. Or maybe taking this intuition too far beyond just a rule of thumb is a foolish endeavor. You can decide! I’m not claiming I’m absolutely right here, just that this is what I’ve seen happen so far in my work.
You can Train Intelligence and Logic into LLMs
Just like training facts into an LLM by showing these facts discussed across many documents and many conversations, you can also train certain behaviors and “logic” into an LLM. The wider the range of behaviors you give to an LLM during training, the smarter I believe it becomes.
Example time, so you know I’m not entirely talking out of my ass. In a recent project, I used “negative” conversations. A “negative” conversation is one between a questioning human and an AI, where the questioning human asks misguided or incorrect questions (e.g., “why is 2+2=5?”) and the AI must first correct the question, then explain the actual correct answer (e.g., “2+2 is not 5. 2+2 is actually 4.” Though these negative conversations were generated from the same seed data as the usual question-answer stuff, adding them contributed to making the LLM significantly smarter, and more robust.
In other words, showing the AI how to approach problems from a different angle, and deal with a foolish user, helped make it smarter and better at conversation. I believe this is because it constrained the LLM’s “range of behavior” to something closer to reality — the user is not always right, and should not always be agreed with. Finetuning, to me, is about more than just giving an outlet for the information learned during pretraining — you’re teaching the LLM how to think. And variety is key.
Interpolation is easier than Invention
LLMs can go beyond what they’ve seen during training. They can make inferences based on their “big picture” understanding; they can infer things from context, especially if few-shot examples are given. They can roll the dice and come up with a nat 20. However, if you want the AI to be reliable, don’t force it to reinvent the wheel every time — train it on a diagram of one.
Since LLMs can combine behaviors they see in training data, and those behaviors help constrain the range of the LLM’s output, it feels to me that the path to smarter, more resilient LLMs lies in varied, complementary, intelligent training data. A large number of logical points that the LLM can interpolate between to easily and reliably behave in a number of different ways. In my most recent project, I gained a huge intelligence improvement by teaching the model how to say “No, actually…” in addition to “yes”. The question is — what behaviors should be added after that, what effect will they have, and how do we generate this data at scale?
These are good questions, and I don’t know their answers yet. But it definitely seems like a reliable way for LLM trainers to improve the intelligence of their models is to show them a variety of reasoning. I also think scale is important here, because the intelligence improvement came *after* I added generalist assistant data, which no doubt was more varied — but also more dispersed — than simple “yes” and “no” questions.
Going back to the headline of this section — LLMs can be really impressive at times because they can make extrapolated inferences beyond what they’ve seen, beyond their range of behavior… but don’t count on it. Try to set up your dataset such that the LLM naturally understands how to do what you want it to.
Conclusion
Having intuitive understanding for the way LLMs learn and understand the behaviors you show them, is key to training good models.
Understanding combination of individual behaviors is part of that.
I’ll do more experimentation with this and write more about it in the future.
If you want a connection to prompting — think about the few-shot examples you write as tweawking the “range of behavior”. I don’t think that single concept explains everything — it’s a gross simplification — but it may be a useful mental construct.
Alright, that’s all for this week. Have a good one and I’ll see you next time!
Great general principles in this article. Much thanks!