
Mistral-Next and Mistral-Medium: Smart, but Stubborn?
The new models are more like GPT-4 — for better AND for worse

I’ve talked before about how prompting open-source models is often about delicately crafting an intricate pattern of examples, while prompting big closed-source models like GPT-4 “feels more like whack-a-mole with ‘don’t do X! don’t do Y! You MUST do Z!’ etc.” After playing around with Mistral Medium, and even Mistral Next in Augmentoolkit, I’ve found some interesting tendencies.
Let’s look at a simple example of the apparent tradeoff made. Firstly, these models are smart. When running Mistral medium, it generated good questions. Here’s one example of such a good question (source paragraph seen at bottom).

The question asks an interesting factual query about the provided source text, and the answer addresses multiple facets of it. The question doesn’t mention “the text” and it follows instructions well, etc.
For reference, the prompt had a bunch of examples that look like this, where each example had four questions:
1.) How does the slope 'm' in a linear function y = mx + b affect the graph of the function?
Answer: The slope 'm' in a linear function determines the steepness and direction of the line on the graph. A positive slope means the line ascends from left to right, while a negative slope indicates it descends. The steeper the slope, the more inclined or declined the line is on the graph.
2.) What role does the y-intercept 'b' play in graphing a linear function?
Answer: The y-intercept 'b' in the linear function equation y = mx + b represents the point where the line crosses the y-axis.
3.) In the equation of a quadratic function y = ax² + bx + c, how does the coefficient 'a' influence the graph of the function?
Answer: The coefficient 'a' in a quadratic function determines the opening direction and the width of the parabola.
4.) Define the concept of a function in mathematics, in one sentence.
Answer: A function is a relationship where each input is associated with exactly one output.
What’s the “worse” in this “better and for worse”?

It made 7 questions. How very eager of it.
Why is making 7 questions a problem? Because the model broke from the pattern the few-shot examples laid out, with this behavior’s “specific cause” lying in the training data of the model. Meaning, you can’t fix it if it’s causing problems.
And it caused a lot of problems. I’ll show some of them, then get to the upshot of it all. All the screenshots are from Mistral Medium, because I didn’t want to burn through a wallet that wasn’t mine more than I already had.

Out of the whole subset (13 chunks), it only made 3 valid conversations. It should have made about 20 (the kind of performance Nous Mixtral gets). This is because the stuff Medium generated consistently failed to pass regex validation which ensures the proper questions are asked and answered in the proper places. This is because the model broke from the pattern laid out in the example, and did its own thing, causing it to fail to make it through the pipeline.
Here are some problems it ran into, just to give you an idea.
Problem: Generating the actual questions during the explicit “Plan-only” prompt. None of the examples include explicit questions.
[I’ve omitted the plan, it’s long, everything not in square brackets is model output]
Note: Questions have been revised to provide context where needed, as mentioned in the prompt.
Questions:
1. What is the main focus of the text with regard to sabotage? (Recall)
2. According to the text, how does simple sabotage differ from other types of sabotage in terms of the individuals involved? (Comprehension of the text's viewpoint)
3. What are some ways simple sabotage can be carried out, according to the text? (Interpretation)
4. How does the text define simple sabotage? (Recall)
5. In the context of the text, how does simple sabotage limit the risk of injury, detection, and reprisal? (Comprehension of the text's viewpoint)
Problem: Including the setting in a conversation, inventing its own format for a conversation, bolding character names, and doing a bunch of other stuff that wasn’t in the example.

Problem: Adding a whole new question to the interview generated for a character card
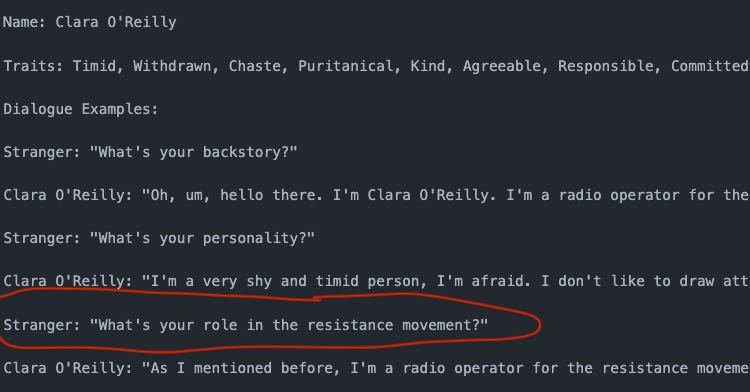
Problem: Good god it added the questions into the dialogue examples

These are not nitpicks. I’m literally scrolling around and picking generations at random, and most of them have pipeline-breaking problems. Either Mistral medium is very very bad at instruction following at normal temperatures (not likely since the error rate was higher during the question generation too, which had temps of 0.2 or similar); or it’s been trained too much after being the base model phase, such that its pattern-continuing ability is near-completely broken. This is not the fault of the prompts: they work fine with Mixtral, and a ton of other open models. If these were nitpicks, more than three conversations would have passed validation. If these were prompt issues, we’d see the same problem consistently, not a grab-bag of different catastrophes. Consistent behavior has a specific cause, and this is anything but consistent.
So why’s this an issue? Because LLMs being able to follow provided patterns makes them useful. Let me argue this with a brief story. Do you know why Augmentoolkit doesn’t use GBNF grammars any more? GBNF grammars are a way of constraining which next token a model generates, so that it satisfies a regex-like pattern. Augmentoolkit, in its earliest versions, relied on grammars to get outputs that could be parsed by code and fed to the next part of the pipeline. However, few-shot examples made grammars obsolete. Because even without the output being forced to follow a format, showing a model that format enough times made it follow the format perfectly 99% of times. The model’s “opinions” and “tendencies” didn’t factor into it. Not so with Mistral Medium (or Next, though its greater smarts allowed it to pass a bit more validation). Few-shot examples served as surefire rails that everything from a 7b to a 70b could reliably follow, with the only difference being the quality of the words within the format.
This is good. The outputs were reliable and could be parsed by code. Hallucination wasn’t even a concern in most cases because the examples showed where to draw the information from and the model learned that in-context. Sure, the models were worse in chat settings, but with examples they became invaluable “thinking cogs” in the machine of a complex pipeline.
With these “smarter” models, its training data and tendencies come into play a lot more. It loves to bold things in creative settings even if I don’t show a single asterisk in my examples. It constantly goes beyond the bounds laid out by examples. It changes headings and whatever else it feels like. You know about GPT-isms, where GPT’s style infiltrates its outputs and makes it obvious an AI wrote it? That’s a stylistic equivalent of this: the model favoring not what it has seen in context, but what it has seen in training data, to the generation at hand. Overfitting. It makes a poor autocomplete, and that makes it a poor pattern-continuer, which makes it impossibly hard to control. It makes it bad for enterprise pipelines. Nous Mistral 7b actually performs better than Mistral Large in Augmentoolkit.
In the case of GPT-4 Turbo this sort of thing makes it basically unsuitable for creative tasks, because its writing is dominated by purple prose, flowery language, “ministrations” and spine shivers. But at least GPT-4 Turbo is smart enough to follow my output indicators, and it gets the format right, even if the style and contents are wrong. But Mistral Medium and Next? Whatever it’s already seen in its training overrides the instructions completely, and its lack of respect for examples makes it go off any rails you lay down within the first few tokens of output. Maybe it chats better, I don’t know. But chat isn’t the main usecase of LLMs, just the most obvious. LLMs allow the injection of “thinking” into an application. Need to make a decision, intelligently process some data, or do something else you’d usually pass off to a human and get it back the next day? You get an LLM to do that.
Chat settings involve a variety of tasks being thrown at the model at the user’s whim; when an LLM is being used as a cog in a machine, it does the same kind of task over and over and over, according to the delicate nuances laid out in the examples. You see this a lot in SAAS and Enterprise AI products, and it’s a similar idea with Augmentoolkit, through which I’ve gained months of experience in this very narrow area (worth a lot more than it sounds like in the fast-moving AI climate).
But the point is, if the training data overrides what the model sees in its examples, it — as a thinking cog in the machine — stops turning reliably, and brings the whole operation to a halt. At that point, who cares if it has more coherent chats, where users typically don’t provide detailed instructions? It’s just become unusable in 90% of its use cases!
And, unless I’m missing a big bug in my code, or a sampling parameter issue, Mistral Medium and Mistral Next are very much afflicted with the inflexibility of GPT-4 Turbo. Only they aren’t quite as smart, so I can’t get the AI to stop doing the wrong things by telling it not to do them. Even if the AI would, we’d be back at whack-a-mole, which is not systematic, too inflexible for high-quality production applications, and honestly? Frustrating as hell to do.
I love Mistral AI, and I love their models. I use Mixtral all the damn time—that thing’s great at pattern following, if you’re not using the official instruct tuning (the Nous Hermes 2 DPO finetune of Mixtral is really really good). Maybe if Mistral open sources Mistral Next we’ll get finetunes that are better at following patterns, it’s quite probable that this is a symptom of their instruct-tuning and continued training approaches. I will say that this emergent habit of the model means they’re getting close to GPT-4. But what not enough people are noticing is that this means we’re getting closer to the problems associated with GPT-4, too.
To the people training base models out there, please don’t ignore the utility of following a pattern. If someone from Mistral reads this (less of an impossibility than I would’ve assumed at the start of this month), please take into consideration the ability to follow few-shot examples in your next instruct tuning run.
The questions Medium and Next generated were really smart and insightful. I want to believe in that. The pattern following is just a problem to fix.
Alright, that’s the main argument of this post done. I’ll make the other news and misc section short. Augmentookit’s API version is almost out. It comes with usability improvements, the ability to use any OpenAI-compatible API (Mixtral included), and a unification of all the branches (so Aphrodite will live there too). The changes are actually pushed, I just haven’t updated the documentation yet.
I mentioned I’m doing prompt consulting for API-using AI startups in the previous post. Why am I mentioning it here? Because I’m a shill for myself :)
That’s all for this week. Thank you for reading and see you next time! May your patterns be elegant and your outputs consistent.