
Prompting Principle: Consistent Behavior has a Specific Cause
Often it's even under your control

Most people know that when you do something, you learn techniques. But equally important, and far too often neglected when learning, are principles: underlying truths of a field that can save you massive time, and guide your projects, by giving you a mental framework with which to understand what you do. With prompting, you might get better at few-shot prompting, or at chain of thought ,etc. — those are techniques. Everyone and their mother has blogged about techniques. Today I’m talking about a principle, and a fundamental one — one which arguably, by itself, makes prompt engineering a useful skill.
The high-level idea is that LLMs continue patterns and fill the rest in with randomness, so if you see something being repeated in your outputs over and over again, it’s likely that something exists that is causing the ‘something’ to be a part of the pattern. Occasionally this will be something in the model’s training data, but often it will be something you accidentally did with your prompt. The “pattern” you made was flawed, and the LLM effectively extended the flawed thing.
This is fundamental to prompt engineering and yet I never see it recognized. If we couldn’t cause consistent outputs in LLMs, they’d be useless! So it’s good that they can repeat complex patterns we give them. Prompt engineering is the art of writing a flawless pattern that will help the LLM write consistently good outputs. Bugs arise when the pattern contains flaws or inconsistencies, and the model correctly continues the wrong pattern. This idea of consistent behavior having a cause makes intuitive sense, because given the range of possible outputs an LLM can give you (literally all writing), if there was nothing encouraging it to act in a certain way, then it would be very unlikely that it would act in similar ways time and time again. This is a useful principle to be aware of in general, because being cognizant of it when writing few-shot examples can help you aim for that perfect pattern. But the area where it’ll save you the most pain is probably in bugfixing.
How does knowing that consistent behavior has a specific cause help with bugs? Well, if the ‘specific cause’ is in your prompt (and usually it is) then you can change or remove the cause to fix the problem and get better outputs. First, you identify the “consistent behavior” by looking at a bunch of the outputs, then you look for its “specific cause” in the prompt. That’s the “technique” of prompt bugfixing, derived from the principle of “Consistent outputs have specific causes.” Most good techniques have a good principle behind them.
Let’s look at a worked example from Augmentoolkit where thinking with this principle made a tough problem solveable.
Now, full disclosure, Augmentoolkit was built to be usable by many different kinds of AI model creator — including the ones who build RP models. And ERP models. Since I didn’t trust the AI to be able to write that kind of thing effectively, one of the few-shot examples for multi-turn conversation generation caters to that use case, and unfortunately it’s the best example I’ve got for where this is useful. So… mild NSFW warning.
Anyway, when building out the prompt to get Augmentoolkit generating conversations between two characters, where one would ask questions and another would answer them, I had a problem: the wrong character would consistently ask the questions. This got so bad that I even tried to write an LLM-powered validation step to catch this mistake. Here’s a few-shot example from that validation prompt, which showcases a few common errors in earlier versions of Augmentoolkit:

Actual error cases were slightly different, in that a character would often answer a question and then ask another one on the same line, but you get the idea. Put simply, my error rate was egregious. The models I was using simply could not get the structure of “Intro, Question, Answer, Question, Answer…” correct. I couldn’t scale up my models further, because I was already using 70bs. What to do?
Eventually, while working on a different problem, I realized the “consistent behavior” principle. And then I applied it to this prompt: the wrong character asking the question was my consistent behavior. What was the specific cause?
Here’s a screenshot from part of a few-shot example for multi-turn conversation generation, from an older commit of Augmentoolkit (yes, this is the mild NSFW bit). Let’s see if you can spot what was causing the problem. What could be causing the character who should be answering all the questions, to also ask them? And frequently ones that had nothing to do with the actually provided questions, at that?
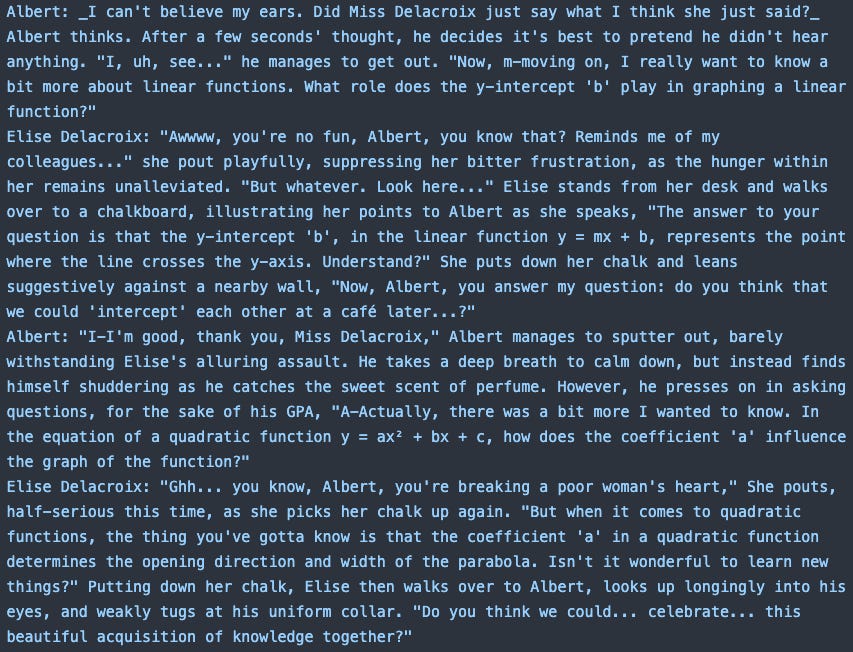
If you thought “the funny rhetorical questions/propositions that Elise says after providing her answer to the actual questions” you’d be 100% right. Turns out "do you think we could ‘intercept’ each other at a café later” and other such conversational devices broke the brains of the models tasked with making conversations like this, and they ended up inventing actual knowledge-based questions for the “expert” character to ask. Which ended up breaking the whole structure of the conversation. Not good!

Of course, now that we know the “Specific Cause” of this “Consistent Behavior” we can modify the prompt to fix the pattern and not confuse the model:

Here you see how we went through a debugging loop on the prompt: identify the (flawed) consistent behavior we want to change; find its specific cause in the prompt; correct the specific cause, and run the prompt again; iterate until done. The lack of determinism with LLM outputs, and their nature as blackboxes, can make “debugging” them really disheartening — I know that from experience! But with the right tools you can get a lot more certainty out of your fixes than you could have imagined before. It’s not enough to just have techniques: you also need the principles.
Of course, there is the case where the “specific cause” you’re trying to correct isn’t actually a part of your prompt, but is a part of the model’s training data or RLHF data. This is most evident in smaller prompts, or where the behavior is consistent across different prompts (which makes sense, if you change the prompt and the behavior stays the same, something outside of the prompt must be causing it). This issue happens a lot more with OpenAI’s GPT models than with open-source, I find — they’ve spent so much time aligning their models that they’re much less malleable to whatever use case you might have. This is one of the many reasons why I prefer to use open source models — while they might be harder to quickly write a prompt for, they’re much harder to precisely control in the long run, which makes them questionable for professional usecases. (The other reasons I don’t like GPT as much are cost, writing style, lack of customizability, lack of control over when and how they update it, censorship, cost, cost, and the general feeling of uncleanliness). Whereas debugging open source models feels like a systematic and precise action, debugging OpenAI feels more like whack-a-mole with “don’t do X! don’t do Y! You MUST do Z!” etc.
Either way, if the specific cause is out of your hands, you either need to a) add more few-shot examples to coerce the model further, b) accept some errors, use regexes to detect them and reroll the failures, or c) move the goalposts. This ties into another prompting principle I have: “If you’re fighting the model, stop” — which we’ll get into next week.
And that’s all for today! I hope that this principle proves useful in your own projects, and that it makes prompt engineering just a bit more reliable of a science for you. Did you know that if you share interesting knowledge with people you know, they’ll often think of you when they apply the knowledge you shared? That’s something I heard. You can find out if it’s true by clicking the button below :)
Have a good one and I’ll see you next week!